
- cross-posted to:
- linux@lemmy.ml
- cross-posted to:
- linux@lemmy.ml
You must log in or register to comment.
I need to catch up on training. I need an LLM that I can train on all my ebooks and digitized music, and can answer questions “what’s that book where the girl goes to the thing and does that deed?”
Existing implementations can probably do that already.
Interesting idea!
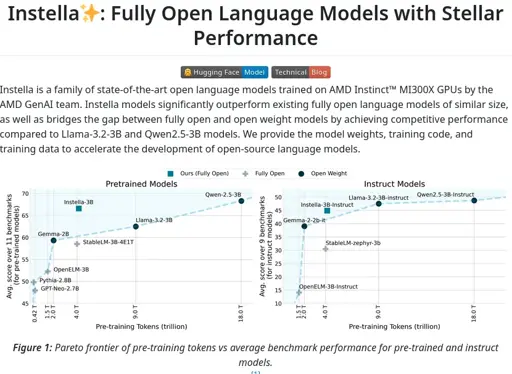
Fully open and accessible: Fully open-source release of model weights, training hyperparameters, datasets, and code, fostering innovation and collaboration within the AI community.
That’s actually pretty good. Seems to be open source as the OSI defines it, rather than the much more common “this model is open source, but the dataset is a secret”.
It knows everything about everything you ever received by mail from your local grocery store.
Can it learn my local database of PDF books I illegally downloaded years ago? No!
That’s right! Isn’t it great?
Huh?
I see all these graphs about how much better this LLM is than another, but do those graphs actually translate to real world usefulness?
I think more of the issue is what constitutes actual open source. This is actually open source, and it performs well. If you’re familiar with the space, then it’s a big deal.
I’m not familiar with the space but realised this was a big deal.
I feel like I need to shower after interacting with any of the other LMs.
Something fully open source will hopefully be embraced by the community and be used for some interesting, useful, and value producing things instead of just attracting venture capital.
I see, thank you.
Damn, they even chose a dataset with a open license.
The problem is… How do we run it if rocm is still a mess for most of their gpus? Cpu time?
Well it’s not necessarily geared towards consumer devices. As mentioned in the writeup, it’s not trained on consumer gear.
Smart people, I beg of thee, explain! What can it do?
Edit: looks to be another text based one, not image generation right?
It’s language only, hence, LM
